


#LM6: Música con IA generativa
La inteligencia artificial (IA) ha emergido como una herramienta poderosa en el ámbito musical, permitiendo la creación de composiciones que antes eran impensables.

La música ha sido una forma de expresión artística desde tiempos inmemoriales. Con la evolución de la tecnología, la forma en que creamos música también ha cambiado drásticamente. La inteligencia artificial (IA) ha emergido como una herramienta poderosa en el ámbito musical, permitiendo la creación de composiciones que antes eran impensables.
Historia de los Modelos Generativos de Música
Históricamente, la generación de música con IA ha pasado por varias fases y técnicas, las más significativas:
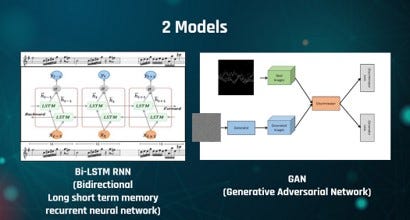
Redes Neuronales Recurrentes (RNN): Estos algoritmos son especialmente buenos para analizar secuencias, como una serie de notas musicales. Se entrenan en música existente y luego generan nuevas composiciones al predecir la próxima nota o acorde.
Long Short-Term Memory (LSTM): Una variante de las RNN, las LSTM son excelentes para aprender dependencias a largo plazo, lo que las hace ideales para la composición musical.
Autoencoders: Estas redes neuronales aprenden a comprimir música en una representación más pequeña, que luego puede ser modificada para generar nuevas piezas.
Generative Adversarial Networks (GANs): En el ámbito musical, las GANs tienen una red que genera música y otra que evalúa su calidad. A través de un proceso competitivo, ambas redes mejoran, produciendo música cada vez más realista.
Además, estos métodos a menudo se combinan con técnicas de procesamiento de señales digitales y algoritmos de aprendizaje no supervisado para crear sistemas aún más avanzados.
La Nueva Era de la Generación Musical con IA
Hoy en día, la generación de música con IA se ha simplificado y se ha vuelto más avanzada. Los modelos actuales se basan en principios similares a los modelos GPT basados en Transformers. Si consideramos la música como un lenguaje, en lugar de predecir la próxima palabra, estos modelos predicen el próximo fragmento de canción.
Recordemos que son los Transformers: Introducidos en el paper "Attention is All You Need", los Transformers son esenciales en el procesamiento del lenguaje natural. Utilizan mecanismos de atención para ponderar la importancia de diferentes tokens en una secuencia. En la música, se utilizan para procesar y generar secuencias de tokens musicales, creando salidas coherentes y de alta calidad.
Así mismo han aparecido un par de proyectos interesante basados en Difusión: Estos modelos introducen ruido en los datos y luego aprenden a eliminarlo, aplicando este proceso a la generación de música. El algoritmo de difusión garantiza que la música generada sea estable y consistente, mejorando con cada iteración.
MusicGEN
MusicGen no es simplemente otro modelo de IA. Lanzado el 8 de Junio por META AI, este modelo es de código abierto, lo que significa que cualquier persona puede probarlo y experimentar con él. A diferencia de otros modelos que se basan en múltiples etapas o encadenamientos, MusicGen opera sobre varios flujos de representación musical discreta y comprimida, es decir, tokens. Utiliza un transformador LM de una sola etapa junto con patrones de entrelazado de tokens eficientes. Esto elimina la necesidad de encadenar varios modelos de IA o neuronales. Gracias a este enfoque, MusicGen puede generar muestras de alta calidad mientras se condiciona en descripciones textuales o características melódicas, ofreciendo un control sin precedentes sobre la salida generada.
De Texto a Melodía
El principal atractivo de MusicGen es su capacidad para transformar texto en música. Utiliza la arquitectura Transformer de Google, que ha revolucionado el campo de la IA generativa. Pero en lugar de predecir palabras, como en modelos como ChatGPT, MusicGen predice fragmentos musicales.
El proceso comienza con el "tokenizador" de audio de Meta, que descompone los datos de audio en componentes más pequeños. Con un entrenamiento basado en 20.000 horas de música licenciada, y un enfoque especial en un conjunto interno de 10.000 pistas de alta calidad, MusicGen está preparado para generar música basada en cualquier prompt descriptivo que se le proporcione.
Características y Aplicaciones
MusicGen no solo se limita a generar música a partir de texto. También permite la combinación de texto con fragmentos musicales para obtener resultados sorprendentes. Aunque los resultados pueden variar, las posibilidades de remezcla son prácticamente infinitas. Para obtener los mejores resultados, se recomienda proporcionar prompts de texto precisos y completos.
Además, MusicGen supera a otros modelos en el mercado, como Riffusion o MusicLM de Google, según evaluaciones que combinan métricas objetivas y subjetivas.
Accesibilidad y Futuro
Lo más destacado de MusicGen es su naturaleza de código abierto. Tanto el código como los modelos están disponibles en GitHub, y se permite su uso comercial. Esto representa una oportunidad para artistas, desarrolladores y entusiastas de experimentar y colaborar en el ámbito de la música generativa.Podéis probarlo y encontrar varios ejemplos de su uso aquí: https://huggingface.co/spaces/facebook/MusicGen
Riffusion: Transformando Texto en Música a través de Espectrogramas
Riffusion es un proyecto concebido por Seth Forsgren y Hayk Martiros. Su principal objetivo es utilizar la IA para generar imágenes a partir de texto. Pero no cualquier tipo de imágenes: Riffusion está diseñado para producir espectrogramas, representaciones visuales de sonido. Estos espectrogramas, a su vez, pueden transformarse en clips de audio, permitiendo a Riffusion crear música basada en descripciones textuales.
El Corazón de Riffusion: Stable Diffusion
El modelo de IA que impulsa Riffusion es el Stable Diffusion, un modelo de código abierto. Una de las características más destacadas de este modelo es su capacidad para generar infinitas variaciones de un prompt simplemente cambiando la semilla. Además, es compatible con diversas interfaces de usuario web y técnicas, como img2img, inpainting, prompts negativos e interpolación.
Espectrogramas: Visualizando el Sonido
Un espectrograma es una representación gráfica del contenido de frecuencia de un sonido. En él, el eje x simboliza el tiempo, mientras que el eje y denota la frecuencia. Cada píxel en el espectrograma refleja la amplitud del audio en una frecuencia y tiempo específicos. Para obtener un espectrograma a partir de un audio, se utiliza la Transformada de Fourier de Tiempo Corto (STFT), que descompone el audio en ondas sinusoidales de diferentes amplitudes y fases.
Funcionalidades Adicionales de Riffusion
Riffusion no se limita a la generación de espectrogramas. También ofrece la opción de generación de imagen a imagen, ideal para modificar sonidos manteniendo la estructura de un clip original. Mediante el parámetro de fuerza de desruido, los usuarios pueden controlar cuánto se aleja el resultado del clip original y cuánto se acerca a un nuevo prompt.
Adicionalmente, Riffusion ha lanzado una aplicación web interactiva. Esta herramienta permite a los usuarios escribir prompts y generar contenido interpolado en tiempo real, visualizando simultáneamente la línea de tiempo del espectrograma en 3D.
Acceso al Proyecto
Para aquellos interesados en explorar más a fondo Riffusion, el código, ejemplos y modelos están disponibles en su repositorio de GitHub.
Podéis probarlo aquí:

En resumen, Riffusion es un testimonio del poder de la IA en el ámbito musical, ofreciendo una nueva forma de experimentar y crear música a partir del texto.