


#LM14: Gemini Difussion: Modelos de Difusión para Generación de Texto. ¿Son los dLLMs el futuro?
Los modelos de difusión dLLMs emergen como una prometedora alternativa a los modelos generativos secuenciales tradicionales en tareas de generación de texto. Los resultados son inicialmente flipantes.

Esto no para :) . Hace poco me encontré con este post en X que me llamó muchísimo la atención.

y mi HYPE creció enormemente cuando me encontré esto también:
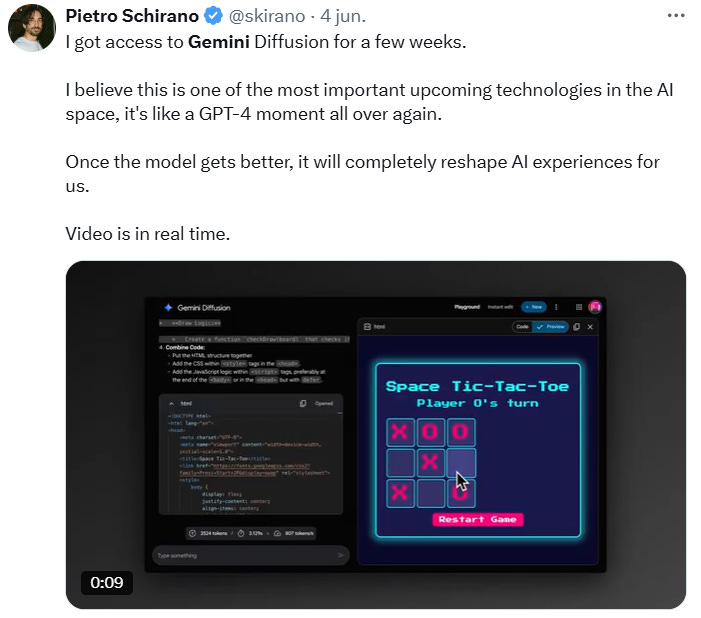
Pero… ¿los modelos de difusión no eran la base usada en la generación de imágenes y música? ¿Qué pintan estos modelos prediciendo textos? ¿Acaso tienen estas tecnologías capacidad de razonar?
Entendiendo los basics
En los últimos años se han estandarizado varias tecnologías y modelos como fundamentales en IA Generativa: Entre ellos, las arquitecturas basadas en transformers (GPT) que han permitido generar texto con una calidad nunca antes vista y los modelos de difusión que han ayudado a generar imágenes y audio con increíble realismo. Repasemos brevemente en qué se basan estos modelos:
Generando texto - Modelos GPTs (Generative Pre-trained Transformer)
Los GPT se basan en la arquitectura Transformer, cuya pieza central es el mecanismo de auto-atención: básicamente la red aprende a ponderar qué palabras de una oración son relevantes para predecir la siguiente, sin procesarlas en orden estricto.
Primero se somete a un pre-entrenamiento masivo con textos sin etiquetar (decenas de miles de millones de palabras); durante esta fase aprende gramática, hechos y estilo de forma autosupervisada. Posteriormente, se ajusta con datos específicos o con técnicas de alineación (p. ej., RLHF) para tareas concretas como diálogo o redacción técnica.
En inferencia (el proceso de llegar a una conclusión o deducción a partir de información disponible), el modelo recibe un prompt y predice el siguiente token (palabra o sub-palabra) de forma autoregresiva, añadiéndolo a la secuencia y repitiendo el ciclo hasta completar la respuesta. Este proceso token-a-token es lineal y permite gran coherencia local; combinado con miles de millones de parámetros y el contexto completo en cada paso, produce texto fluido y más que razonablemente pertinente. La familia GPT ha evolucionado aumentando parámetros y datos, lo que ha extendido sus capacidades a tareas de razonamiento, síntesis y generación multimodal.
Generando imágenes y audios - Modelos de Difusión (Denoising Diffusion Models)
Los modelos de difusión adoptan una lógica opuesta: durante el entrenamiento se añade ruido a los datos originales paso a paso hasta convertirlos en ruido puro; la red neuronal aprende la operación inversa, es decir, a desruidar (denoising) progresivamente para recuperar la señal original.
Es decir, entrenas una red neuronal capaz de ir desde la niebla y una imagen con ruido a una imagen coherente. Aquí tenéis un fantástico post que me ayudo en su día a entender el proceso.
En definitiva, una vez entrenado, el modelo comienza la generación con ruido al 100 % y aplica decenas de iteraciones de denoising para “esculpir” un resultado coherente (imagen o audio). Cada iteración opera sobre el ejemplo completo, lo que facilita paralelizar el cálculo y mantener la coherencia global.
Difussion en Texto
Ok! pero, ¿Qué pasaría si cambiamos el status quo y aplicamos la difusión a la generación de texto?.

Podemos aplicar la misma idea de entrenamiento por difusión sobre textos y representaciones continuas o discretas de palabras. Es decir, en el proceso de inferencia de estos modelos, y tomando como origen un prompt y una “niebla de palabras/pensamientos” ¿podríamos usar difussion para generar texto y pensamientos desruidando en capas esos razonamientos textuales para convertirlos en algo coherente?
En lenguaje natural surgen desafíos particulares: el texto es una secuencia de símbolos discretos (tokens), no un espacio continuo. Esto dificulta aplicar directamente la difusión que tan bien funciona en imágenes con píxeles continuos.
Aunque aún es un área por desarrollar el esfuerzo ofrece ventajas claras: generación muy rápida al refinar todos los tokens en bloque y un control más directo sobre atributos de la salida. El principal reto es reducir los pasos necesarios sin perder calidad y garantizar sintaxis correcta en cada fase del denoising.
Dos caminos para hacer “difusión” con palabras
Desde 2021 la comunidad ha seguido dos grandes rutas para que la técnica de difusión —nacida en imágenes— funcione también con texto. La idea general es siempre la misma: empezar con ruido y limpiarlo paso a paso hasta que aparece una frase coherente. Lo que cambia es dónde colocamos ese ruido.
Primera opción: Difundir en el espacio continuo de los embeddings
Piensa que cada palabra se convierte en un vector de números (embedding), como coordenadas en un mapa de significados.
Se añade ruido gaussiano a esos vectores hasta que quedan irreconocibles.
El modelo aprende a “des-ruidar” los vectores y, al final, los vuelve a traducir a palabras.
Ejemplo: Diffusion-LM (Li et al., 2022) demostró que esta técnica permite controlar el texto: puedes pedirle que siga cierta métrica poética o cambie el tono sin volver a entrenar el modelo. Pero aquel primer prototipo aún era algo lento y menos fluido que un GPT. Modelos de referencia:
Difformer añade una “pérdida ancla” y reajusta los niveles de ruido para estabilizar el entrenamiento, alcanzando resultados muy sólidos en traducción y resumen.
DiffuSeq aplica la misma idea a tareas seq-to-seq (por ejemplo, traducir frases completas) y logra rendir tan bien —o mejor— que varios Transformers de modelos GPT, con la ventaja extra de generar salidas más variadas.
En pocas palabras: trabajar en el espacio continuo facilita controles finos, pero exige cuidar mucho la estabilidad y el tiempo de muestreo.
Segunda opción: Difundir en el espacio discreto de los tokens
Aquí no se pasa por vectores: se añade ruido directamente a la cadena de palabras. Imagínate borrar algunas palabras y sustituir otras al azar cada vez que pulsas un botón, para luego enseñarle al modelo a recuperar el texto original paso a paso.
Ejemplo: D3PM (Austin et al., 2021) diseñó matrices de transición que “ensucian” el texto de forma gradual y semánticamente coherente (no toda la corrupción es aleatoria), logrando buenos resultados incluso con vocabularios grandes. Modelos referentes de esta técnica:
Diffusion-BERT reaprovecha un BERT ya pre-entrenado como punto de partida y lo conecta a un proceso de difusión discreto; con ello aumenta la fluidez y sube el BLEU frente a D3PM y Diffusion-LM.
Masked-Diffuse LM introduce “enmascarado suave” en vez de ruido puro y hace la predicción con entropía cruzada en cada paso: se entrena más barato y rinde mejor.
La ventaja de este camino es que nunca se sale del vocabulario real, lo que ayuda a mantener la gramática a raya; el precio es diseñar cuidadosamente cómo se añade y se retira el ruido para no bloquear el aprendizaje.
¿En qué punto estamos?
Ambos enfoques han madurado rápido y ya compiten con los Transformers tradicionales en varias tareas específicas. El primero (la línea continua) brilla cuando necesitas fine-tuning creativo y controles muy detallados; el segundo (la línea discreta) resulta práctica cuando quieres aprovechar modelos de lenguaje ya entrenados ofreciendo más creatividad y cuidar la sintaxis desde el primer paso. Dentro de esta tecnología destacan varias iniciativas recientes:
Inception Labs – Mercury (2025): La startup Inception Labs, fundada por investigadores de Stanford, salió de la fase stealth a principios de 2025 presentando Mercury, anunciado como “el primer modelo comercial de lenguaje basado en difusión”. Mercury, específicamente en su versión Mercury Coder, demostró de forma pública las promesas de velocidad de los dLLMs: es capaz de generar texto hasta 10 veces más rápido que modelos GPT-4 optimizados, alcanzando más de 1000 tokens por segundo. Mercury produce los tokens en paralelo en lugar de secuencialmente, reduciendo drásticamente los tiempos de respuesta sin sacrificar calidad perceptible.. Mercury sirvió como prueba de concepto de que los dLLMs pueden “mantener el tipo” frente a LLMs clásicos e incluso superarlos en eficiencia. Se llegó a reportar declaraciones entusiastas de varios expertos: “es cuestión de 2 o 3 años para que la mayoría de la gente empiece a pasarse a modelos de difusión”. Este lanzamiento catalizó la atención de grandes empresas, y no por casualidad...
Google – Proyecto Gemini Diffusion: En mayo de 2025, Deepmind anunció en preview su experimento Gemini Diffusion, descrito como un modelo de investigación puntero que explora “lo que la difusión significa para el lenguaje y la generación de texto”. De hecho, Google se posicionó así como la primera gran compañía en aplicar la generación por difusión al texto en sus productos, marcando un hito ya que hasta entonces la comunidad asumía que la autoregresión era la única vía Gemini Diffusion todavía no es público masivamente (los usuarios interesados deben unirse a una lista de espera para probarlo), pero los primeros testers han compartido impresiones muy positivas. Se reporta que el modelo responde con asombrosa rapidez (del orden de 1–2 segundos) manteniendo gran precisión. Aunque faltan detalles técnicos (Google no ha publicado aún un paper detallado), la integración de este sistema con las capacidades lingüísticas de Gemini sugiere un modelo híbrido poderoso.
Es decir, utilizaría un modelo de transformes clásico como Gemini y se utilizaría la variabilidad de la difusión en la generación rápida de opciones de salida multimodal y el fine-tunning de ciertos procesos.
Además, Google está utilizando esta tecnología en productos de imagen y video: la plataforma Flow AI, que integra de manera unificada las capacidades de vídeo (Veo 3), imagen (Imagen 4) y lenguaje (Gemini) para creación multimedia Esto significa que un usuario puede, por ejemplo, generar automáticamente un video (vía Veo 3) y a la vez obtener narrativas, audio o descripciones generadas por el módulo de texto de Gemini Diffusion. Detrás de este tipo de videos tan increíbles que mezclan texto + audio + video está Gemini Difussion.
El futuro próximo
Los dLLMs (modelos de lenguaje por difusión) ya se están aplicando allí donde la latencia es crítica multiplicando por cinco la velocidad de los LLMs autoregresivos más rápidos. Esa rapidez permite asistentes conversacionales que entregan párrafos completos en uno o dos segundos y, en entornos de I+D, habilita “pair-programming” casi instantáneo: el modelo autocompleta funciones, reescribe bloques de código o sugiere correcciones sin interrumpir el flujo del desarrollador.
En el horizonte próximo, la misma eficiencia hace viables simulaciones multi-agente donde decenas de agentes generen diálogos y acciones en sincronía sin cuellos de botella, lo que abre puertas a videojuegos y simulaciones con NPCs verosímiles o a laboratorios que prueban hipótesis sociales a escala.
Además, la capacidad de detalle fino propia de la difusión facilita redactar documentos técnicos, médicos, etc. bajo reglas estrictas—por ejemplo, informes clínicos que mantengan terminología precisa o resúmenes científicos adaptados a distintas audiencias—reduciendo carga editorial y riesgos de inconsistencia.
En definitiva, el enfoque híbrido de estas tecnologías Transformers + Diffusion nos permitirán tener en breve una mejora más que significativa en aquellas tareas que requieran “real-time" y/o precisión semántica y sintáctica en generación de textos técnicos con gran calidad. Y, sobre todo, sistemas multiagentes a gran escala que se coordinen en tiempo real, lo que será un paso fundamental hacia la inteligencia artificial general colectiva.